
Python修养4

Python修养4
flowwalkerPython修养4
目录
[TOC]
函数式程序设计
思想
函数可以用来给变量赋值
python中的函数是对象, 可像普通变量一样赋值,传值,返回
函数可作为函数的参数
python中的可调用对象( 即可以用
()调用 ) 包括普通函数和实现了__call__方法的类实例1
2
3
4
5
6
7
8
9class A:
def __init__(self,n):
self.n = n
def __call__(self,x):
return self.n + x
def add(x, y, f):
return f(x) + f(y)
print(add(1,10,abs)) #=> 11
print(add(1,10,A(5))) #=> 21lambda表达式可以被赋值给变量, 也可作为函数的返回值和参数
回顾
filter(function,iterable)挑选出可迭代对象**中每一个满足function的元素返回一个迭代器trick:
1
2
3
4b=lambda x:lambda y:x+y
#b是一个lambda表达式, 返回值是一个lambda表达式
a=b(3) #暂时存放3
print(a(2)) # 5⚠️函数内部声明的变量自动视为局部变量
⚠️可以直接读取外部全局变量, 但是若要修改🌊需要
global x的声明
闭包(closure)
能够维持外部变量值的函数
⚠️修改维持的变量要使用
nonlocal x声明告诉python不要创建局部变量, 要去外围func函数中查找x并修改
1 | def func(x): |
闭包的作用
调用/补充别人的库函数而不修改别人的库
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class DummyNet():
def __init__(self, weight, bias):
self.weight = weight
self.bias = bias
def forward(self, input):
return input * self.weight + self.bias
def __call__(self, input):
return self.forward(input)
# 使用方式
import numpy as np
data = np.array([-1., 0., 1., 2.])
mynet = DummyNet(weight=2.0, bias=-1.0)
print(mynet(data)) # array([-3., -1., 1., 3.])
- 场景
- 别人写好了库(如
DummyNet),不能改源码 - 但需要修改运行流程(如给线性层加 ReLU 激活)
- 闭包写法
1 | def my_forward(self): # 外层函数接收 mynet 实例 |
内层 forward 函数捕获了外层 self 变量(即 mynet 实例),即使外层函数执行完毕,self 仍然被内层函数"关"在里面,随时可用。
1 | print(mynet(data)) # array([0., 0., 1., 3.]) |
等价于:
2
3
4
5
# self = mynet
# 返回一个绑定了 self 的 forward 函数
# 等价于:
mynet.forward = lambda input: np.maximum(0, input * mynet.weight + mynet.bias)
偏应用函数(Partical Application)
用于固定函数中的某些参数
1 | from functools import partical |
迭代器
基本概念
能用
for i in x形式遍历的对象x称为可迭代对象(iterable)可迭代对象必须实现迭代器协议, 即
__iter__()和__next__()方法- 前者方法返回对象本身
- 后者方法返回下一元素
for i in x循环中python会自动调用x.__iter__()方法获得迭代器p, 并自动调用next(p)获取元素, 并自动检查StopIteration异常, 碰到即结束(否则无限循环)1
2
3
4
5
6
7
8
9
10x = [1,2,3,4]
for i in x:
print(i)
#→ 等价于
it = iter(x)
while True:
try:
print(next(it))
except StopIteration:
break #空语句,什么都不做
操作
获取与移动
1 | x=[1,2,3,4] |
若到达末尾, 执行next将抛出异常
设置类迭代器
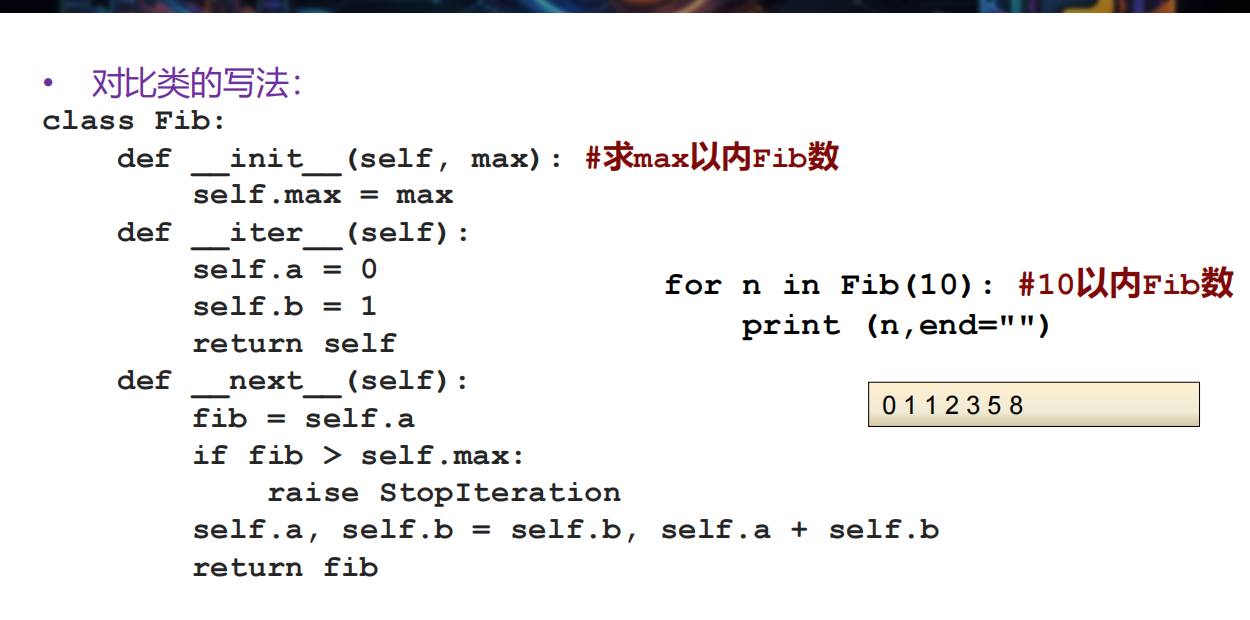
1 | class MyRange: |
更佳的复用方式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def __init__(self, n):
self.n = n
def __iter__(self):
return MyRangeIterator(self.n) # 每次新建迭代器!
class MyRangeIterator: # 迭代器:存状态(i, n)
def __init__(self, n):
self.i = 0
self.n = n
def __iter__(self):
return self #可不写
def __next__(self):
if self.i < self.n:
val = self.i
self.i += 1
return val
raise StopIteration()
x = MyRange(5)
print([i*i for i in x])
print([i for i in x])
it=iter(x)
print(next(it))
print(next(it))
for i in x:
print(i) #才不会阶段输出
# [0, 1, 4, 9, 16]
# [0, 1, 2, 3, 4]
# 0
# 1
# 0
# 1
# 2
# 3
# 4
迭代重载
只写 __getitem__,不写 __iter__,for 循环照样能跑。
1 | class stepper: |
Python 的 for 循环有回退机制:
1 | for item in X: |
实际执行逻辑:
1 | # 第1步:找 __iter__ |
过程拆解
1 | X.data = 'Spam' |
stepper 本身没有状态。每次 for 循环,Python 都新建一个临时迭代器(从零开始计数),所以:
1 | print(list(X)) # ['S', 'p', 'a', 'm'] |
生成器(generator)
概念
- 一种延时求值对象, 内部包含计算过程, 真正需要时才完成计算
例子:
2
3
4
5
6
7
print(a) #<generator object <genexpr> at 0x105b27b90>
for x in a:
print(x,end=' ')
#0 1 4 9 16
#后面就迭代不了了
2
3
4
5
6
7
8
9
10
11
12
13
# matrix 是生成器,其元素也是生成器
for x in matrix:
for y in x:
print(y,end=" ") # 0 1 2 3 4 5 6 7 8
#区别于写法二
# matrix = ([i*3+j for j in range(3)] for i in range(3))
# # matrix 是生成器,其元素也是生成器
# for x in matrix:
# for y in x:
# print(y,end=" ") # 0 1 2 3 4 5 6 7 8延迟绑定Late Binding
写法1如果先全部取出再遍历,结果会错:
2
3
4
5
6
7
8
rows = list(matrix) # ❌ 先全部取出来
for row in rows:
print(list(row))
# [6, 7, 8]
# [6, 7, 8]
# [6, 7, 8] ← 全是 i=2 的结果!为什么?
内层生成器
(i*3+j for j in range(3))没有立刻算,它只记住了"以后要用i"。当
list(matrix)把外层迭代完后,i的最终值是2。之后你再遍历内层生成器,它们才想起来去查i,但此时i已经是2了。
2
3
4
# gen0: "等我运行时,去看看 i 是多少" → 运行时 i=2
# gen1: "等我运行时,去看看 i 是多少" → 运行时 i=2
# gen2: "等我运行时,去看看 i 是多少" → 运行时 i=2写法2没问题,因为内层列表推导式立即计算:
2
3
4
5
6
7
8
rows = list(matrix)
for row in rows:
print(row)
# [0, 1, 2]
# [3, 4, 5]
# [6, 7, 8] ✅ 正确!列表推导式在
i=0,1,2的当下就把值算好存进列表了,不会受后续i变化的影响。写法1什么时候是对的
边取边用,在内层生成器被消费时,外层还没跑完:
2
3
4
5
6
7
for row in matrix: # 外层取一个
print(list(row)) # 内层立刻消费 ✅
# [0, 1, 2]
# [3, 4, 5]
# [6, 7, 8]
- 与列表解析式(即列表推导式list comprehension)区别:
i=(x+1 for x in lst)生成器表达式, 不需要生成结果列表, 延时求值print([x+1 for x in lst])列表解析, 生成了结果列表
yield关键字定义生成器
使用了yield的函数称为生成器
1 | def test_yield(): |
使用 yield 实现斐波那契数列:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
a, b, counter = 0, 1, 0
while counter <= n:
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
break
#或
#for i in f:
# print (i, end=" ")好处是:不用事先准备过程需要的所有元素, 仅仅迭代到该元素时才计算, 可以处理♾️
称之为延迟计算 或 惰性求值(lazy evaluation)
send语句
特点
- 带
yield的函数,调用时返回生成器对象(迭代器) - 执行到
yield暂停,下次从断点恢复 - 遍历完即耗尽,不能复用
yield右边产出值给外部,左边接收send()的值
示例
1 | def h(): |
应用⚠️⚠️⚠️
1 | # ========== 1. 生成器做任务控制器(协程/状态机)========== |
双向通信:任务控制器(协程)
调用 生成器内部 next(controller)启动,跑到 yield,产出状态send("start")恢复, action="start",执行逻辑,再yield暂停惰性计算:自定义 map
对比 列表推导式 生成器版 内存 全部存列表 用到一个算一个 返回 列表 生成器对象 多次遍历 ✅ ❌ 只能一次
2
3
4
5
6
7
def myMap(func, iterable):
for arg in iterable:
yield func(arg)
# 等价于
map(func, iterable) # 内置 map 也是返回迭代器陷阱:
list(x)或for遍历完后,生成器耗尽,再次遍历为空。递归回溯:全排列
2
3
4
5
6
7
8
if len(items) == 1:
yield items
for i in range(len(items)):
v = items[i:i+1]
rest = items[:i] + items[i+1:]
for p in perm(rest): # 递归子问题
yield v + p # 拼接产出执行流程(
perm('abc')):
2
3
4
├─ 固定 'a' + perm('bc') → abc, acb
├─ 固定 'b' + perm('ac') → bac, bca
└─ 固定 'c' + perm('ab') → cab, cba特点:
- 深度优先遍历解空间
- 遇到完整解就
yield,不用等全部算完next()和for可混用,共用迭代状态易错点
错误 原因 生成器遍历为空 迭代器已耗尽,需重新创建 send(非None)启动未启动的生成器只能用 next()或send(None)递归生成器没 yield from子生成器的结果需要用 for ... yield或yield from传递
2
3
4
5
6
7
def perm(items):
if len(items) == 1:
yield items
for i in range(len(items)):
rest = items[:i] + items[i+1:]
yield from (items[i:i+1] + p for p in perm(rest))
其他语法特性
eval函数
概念
把字符串看作python表达式请求其值, 返回其值
1 | expression=input("请输入算式") |
compile和exec函数
| 函数 | 作用 | 返回值 |
|---|---|---|
eval | 将字符串看作Python表达式求值 | ✅ 有返回值 |
exec | 执行字符串中的Python语句 | ❌ 无返回值(None) |
compile | 编译字符串为代码对象,供eval/exec使用 | 代码对象 |
1 | # eval有返回值 |
exec可执行多行代码:
1 | exec(""" |
compile提高多次运行效率:
1 | str = "for i in range(0,10): print (i,end = ' ')" |
动态导入模块:
1 | module_name = "math" |
指定作用域
eval和exec可以通过字典指定作用域:
1 | a = 10 |
⚠️ 作用域查找规则:
参数 说明 不提供scope 使用当前全局/局部作用域 提供 scope字典从字典中查找变量 变量不存在 抛出 NameError
反射(reflection)
概念
获取并使用对象的信息
反射的核心是在运行时动态获取对象的属性和方法,并对其进行操作。
1 | class A(): |
四大反射函数:
| 函数 | 作用 | 示例 |
|---|---|---|
dir(obj) | 列出对象的所有属性和方法 | dir(a) |
hasattr(obj, name) | 判断对象是否有指定属性/方法 | hasattr(a, 'x') |
getattr(obj, name) | 获取对象的属性值或方法 | getattr(a, 'x') |
setattr(obj, name, value) | 设置对象的属性值 | setattr(a, 'x', 100) |
1 | a = A(12) |
反射的应用场景:
- 动态调用方法: 根据字符串名称调用对象方法
- 动态配置: 通过配置文件指定要操作的属性名
- 调试 introspection: 查看对象内部结构
- 插件系统: 动态加载和调用模块中的功能
异常处理
try … except
捕获异常,防止程序崩溃:
1 | # 捕获所有异常 |
多分支捕获:
1 | try: |
try … finally
无论有无异常,finally块都会执行:
1 | try: |
异常处理最佳实践:
写法 说明 except:捕获所有异常(过于宽泛,不推荐) except SpecificError:捕获特定异常 ✅ except Exception as e:捕获所有异常并获取信息 try...finally:用于资源释放(如关闭文件) pass空语句,什么都不做
装饰器
基本概念
在不改变原有函数代码的情况下扩展函数功能
也许你已经在深度学习中见过装饰器:
1 | import torch |
自定义装饰器
1 | def good(func): |
带参数的装饰器
1 | def good2(var1): |
用对象做装饰器
1 | class decorator: |
装饰器执行时机:
阶段 行为 定义时 @decorator立即执行,原函数被替换为wrapper调用时 执行的是wrapper函数,其中再调用原函数 三层嵌套解析(带参数装饰器):
2
3
4
5
6
7
def f(x,y): return x*y
# 执行步骤:
# 1. good2(10) → 返回 decorator 函数
# 2. decorator(f) → 返回 wrapper 函数
# 3. f = wrapper (原f被包装)






